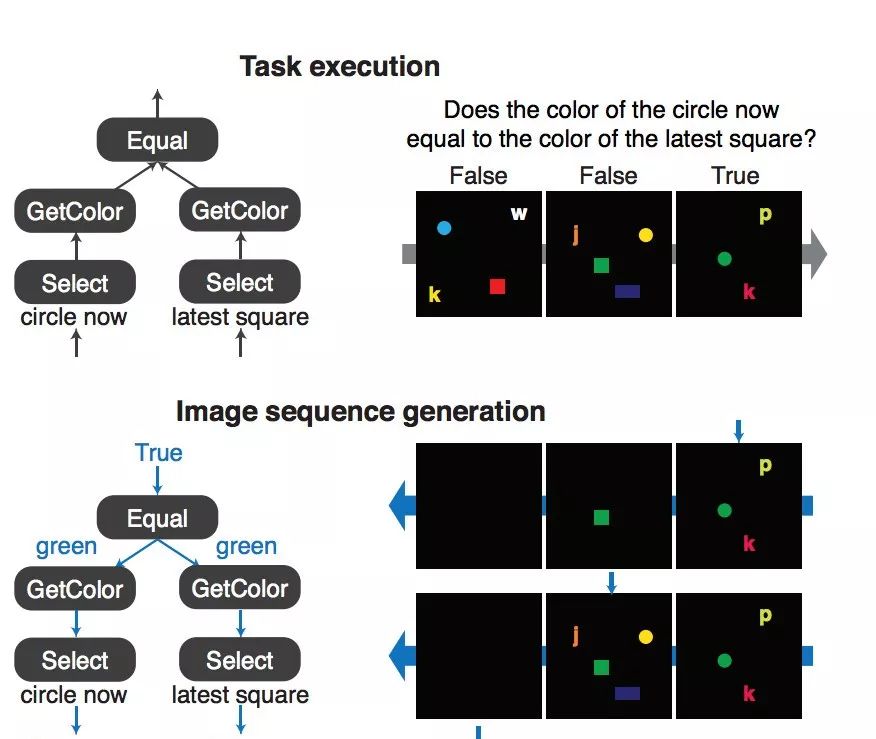
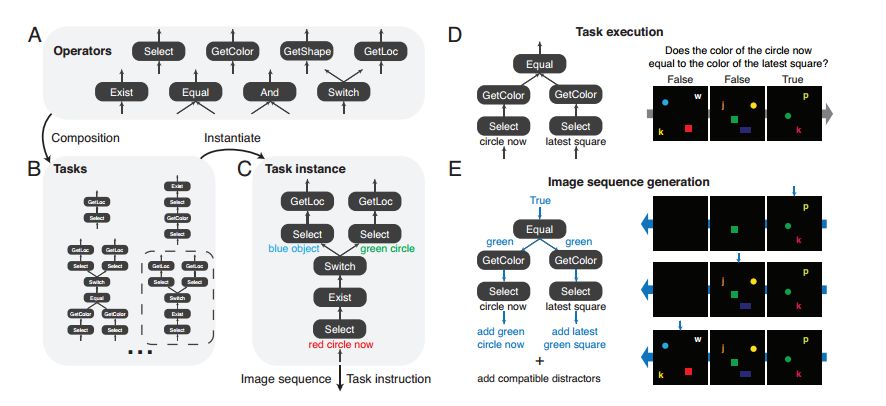
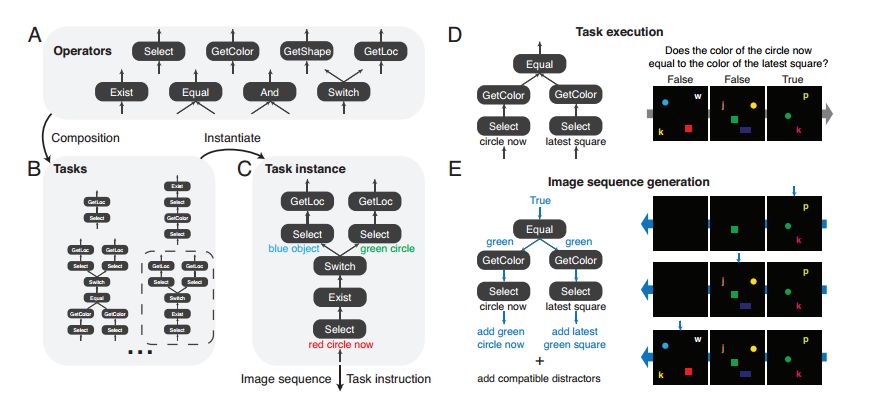
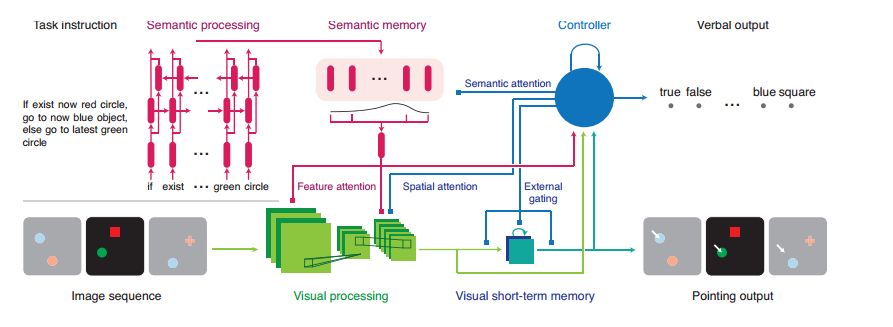
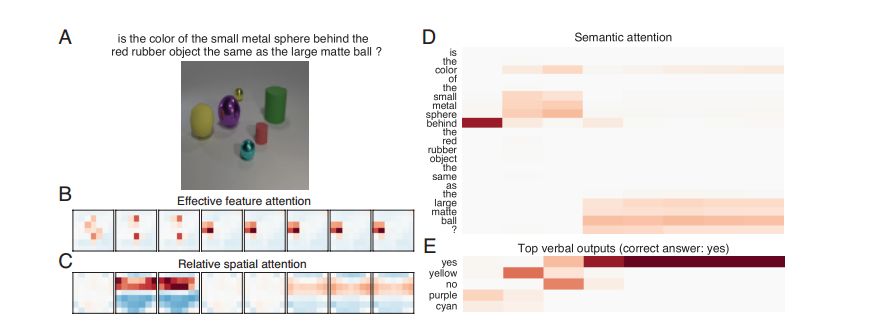
Inspired by the rich visual reasoning and memory traditions of cognitive psychology and neuroscience, we developed an artificial, configurable visual problem and answer data set (COG) for parallel experiments in humans and animals. . COG is much simpler than the general problem of video analytics, but it solves many of the problems associated with visual, logical reasoning and memory—they are still challenging for modern deep learning architectures. It can be said that an annoying problem in artificial intelligence is the reasoning of events that occur in complex, constantly changing visual stimuli, such as video analysis or games. Inspired by the rich visual reasoning and memory traditions of cognitive psychology and neuroscience, we developed an artificial, configurable visual problem and answer data set (COG) for parallel experiments in humans and animals. . COG is much simpler than the general problem of video analytics, but it solves many of the problems associated with visual, logical reasoning and memory—they are still challenging for modern deep learning architectures. In addition, we have proposed a deep learning architecture that excels at other simple settings for diagnosing VQA datasets (such as CLEVR) and COG datasets. However, some COG settings can make data sets more and more difficult to learn. After the training, the network can be generalized to many new tasks zero times. A preliminary analysis of the network architecture trained on the COG shows that the network accomplishes the task in a human-interpretable manner. Figure 1: Sequence of images and instruction samples from the COG data set. The tasks in the COG data set address the problem of target recognition, relationship understanding, and memory manipulation and adjustment. Each task can relate to the current image and the target displayed in the previous image. It should be noted that in the last sample, the instruction refers to "last" instead of "last b". The former excludes the current "b" in the image. (White arrow) shows the target indication response for each image. For the sake of clarity, use high resolution images and appropriate English representations. One of the main goals of artificial intelligence is to create a system that can reasonably and flexibly reason the sensory environment. Vision provides a very rich and highly applicable field to exercise our ability to build a system that can form logical reasoning about complex stimuli. One way to study visual reasoning is the Visual Problem Answer (VQA) data set, where model learning how to correctly answer challenging natural language questions about static images. Although very significant results have been achieved in the study of these multimodal data sets, these data sets highlight several limitations of current methods. First, the degree of training of a model trained on a VQA dataset cannot be determined, simply following the statistical information inherent in the image, rather than reasoning about the logical components of the problem. Second, these data sets avoid the complexity of time and memory, and these two factors play a crucial role in agent design, video analysis and summarization. Figure 2: Generation of a combined COG data set. The COG data set is based on a set of operators (A) that are combined to form various task graphs (B). (C) Instantiate a task by specifying the properties of all operators in the graph. Task instances are used to generate image sequences and semantic task instructions. (D) Forward execution of graphics and image sequences to perform regular tasks. (E) Generating a consistent sequence of images with minimal deviations requires that the graphics be reversed in reverse topological order and passed through the sequence of images in reverse chronological order. In order to address the shortcomings of logical reasoning about spatial relationships in VQA data sets, Johnson and colleagues recently proposed using CLEVR to directly test basic visual reasoning models for use with other VQA data sets. The CLEVR dataset provides artificial, static images and natural language questions about these images, thereby exemplifying the ability of the model to perform logical and visual reasoning. Recent research has shown that the network has achieved impressive performance with near-perfect precision. In this study, we solved the second limitation of time and memory in visual reasoning. The reasoning agent must remember the relevant parts of its visual history, ignore irrelevant details, update and manipulate memory based on new information, and use this memory to make decisions in the coming time. Our approach is to create a human dataset that has many of the complexities of time-varying data while avoiding many of the visual complexity and technical difficulties encountered in processing video (eg, video decoding, Smoothing frames over time). In particular, we have been inspired by decades of research in cognitive psychology and modern systems neuroscience, where anatomy of spatial reasoning has long been based on space and logic. The core components of reasoning, memory composition, and semantic understanding. To achieve this goal, we have established a manual dataset, COG, that can perform visual reasoning concurrent with human cognitive experiments. Figure 3: Architecture diagram of the proposed network The COG data set is based on a programming language that builds a series of task triples: a sequence of images, a language instruction, and a series of correct answers. These randomly generated triples perform visual reasoning in a large number of tasks and require semantic understanding of the text, visual perception of each image in the sequence, and working memory to determine the answers that vary over time (as shown in Figure 1). We've highlighted several parameters in the programming language so that researchers can adjust the difficulty of the problem from easy to challenging. Finally, we introduce a multimodal loop architecture for memory visual reasoning. The network combines semantic and visual modules with state controllers to adjust visual attention and memory for proper visual tasks. After a series of studies, we demonstrate that this model achieves near-state-of-the-art performance on the CLEVR dataset. In addition, the network provides a powerful baseline for achieving good performance on COG data sets in a range of settings. Through ablation studies and network dynamics analysis, we found that the network uses a human-interpretable attention mechanism to solve these visual reasoning tasks. We hope that the COG dataset, the corresponding architecture, and the associated baselines will provide a useful benchmark for the study of visual stimulus reasoning over time. Figure 4: Visualize the thinking process of the proposed network through the attention and output of a single CLEVR sample. (A) Sample questions and images from the CLEVR validation set. (B) Attention to the effective features of each thinking step. (C) Relative spatial attention map. (D) Semantic attention. (E) The top five language output. Red and blue indicate stronger and weaker, respectively. After paying attention to the characteristic attention of the "small metal sphere" and the spatial attention of the "behind the red rubber object", the color of the object (yellow) is reflected in the language output. Later, in the process of thinking, the network paid attention to the characteristic attention of the “big matte ballâ€, and at the same time, the correct answer (yes) appeared in the language output. In this study, we created a composite, combined dataset that required a system to perform various tasks on image sequences based on English instructions. The tasks contained in our COG data set have tested a range of cognitive reasoning skills, and it is especially important that this requires explicit memory of past goals. The data set has minimal deviation and high configurability and is designed to generate rich performance metrics through a large number of specified tasks. We also constructed a cyclical network model that uses attention mechanisms and gating mechanisms to process COG data sets in a natural and humane way. In addition, the model achieves near-state-of-the-art performance on another visual reasoning data set called CLEVR. The model uses a loop controller to focus on different parts of the image and instructions and to generate the language output in an iterative manner. These iterative attention signals provide multiple windows for the model's step-by-step thinking process and provide clues as to how the model can decompose complex instructions into smaller calculations. Finally, the network can be instantly generalized to completely untrained tasks, demonstrating zero-shot capabilities for new tasks. Vacuum Cleaner Ac Dry Motor,Dry Vacuum Cleaner Deep Cleaning,Dry Vacuum Cleaner Motor,Electric Cleaner Ac Motor Zhoushan Chenguang Electric Appliance Co., Ltd. , https://www.vacuum-cleaner-motors.com