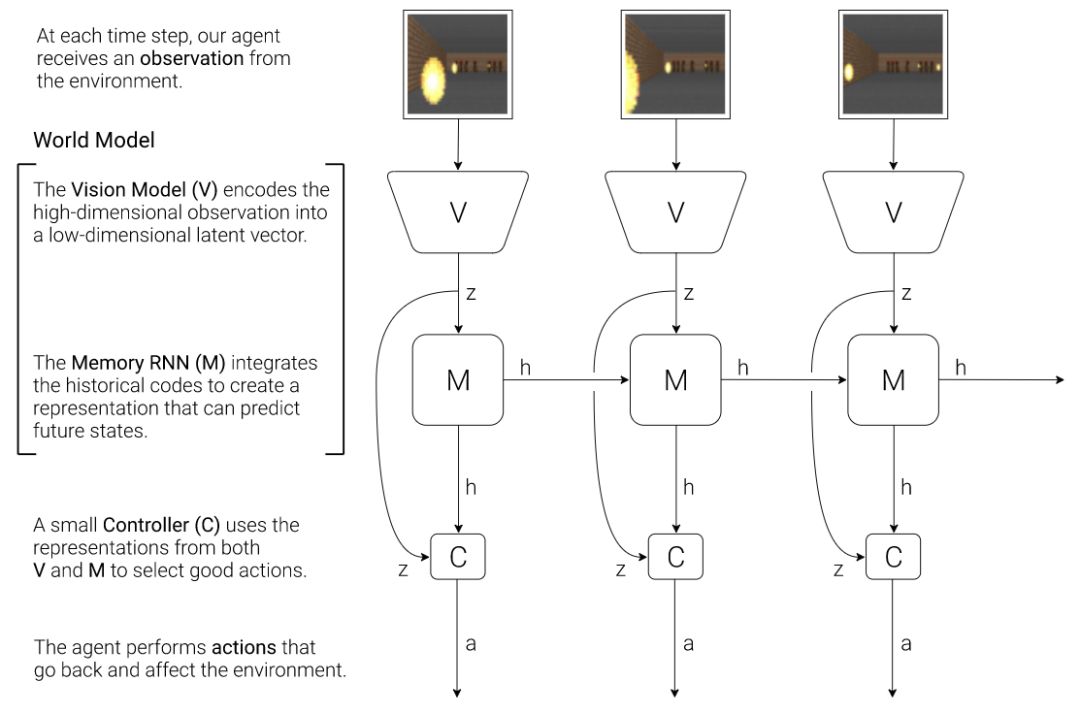
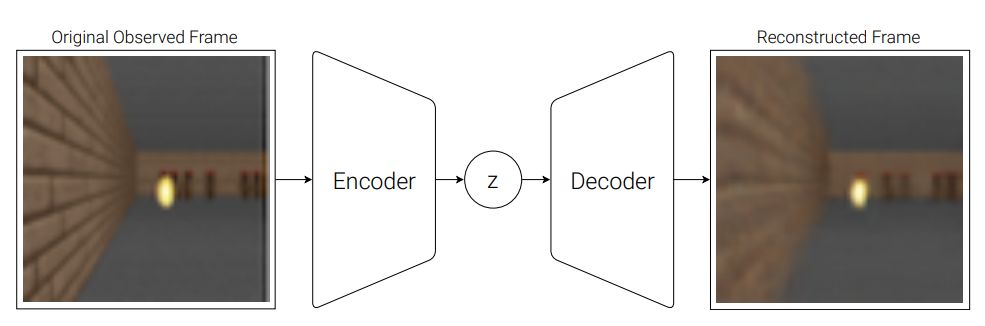
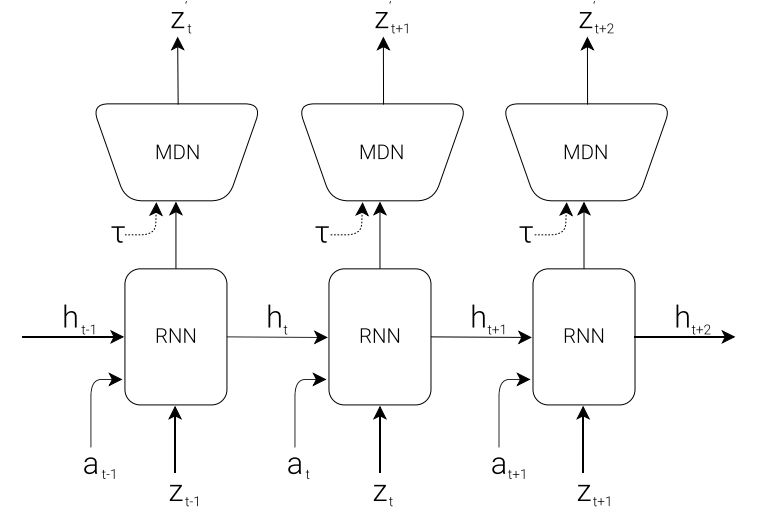
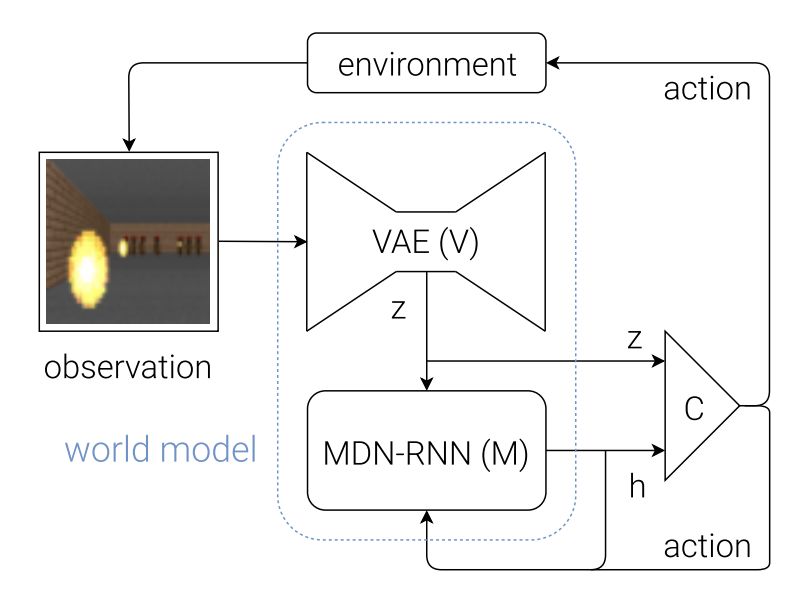
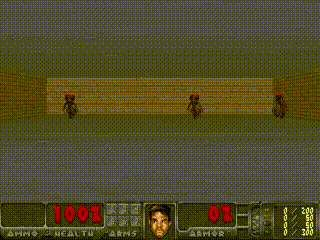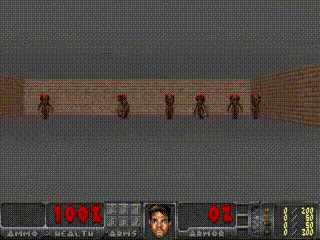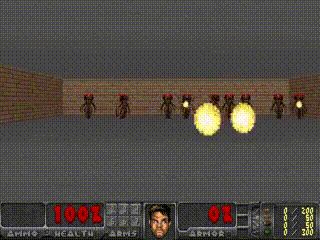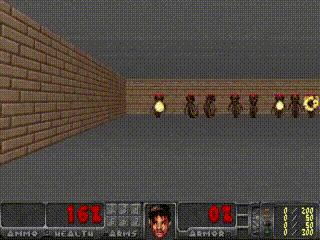
Humans can think in advance in the brain in response to various situations, so can artificial intelligence be used? Recently, the "world model" jointly proposed by Google brain research scientist David Ha and the head of IDSIA of Switzerland AI Lab, Jürgen Schmidhuber (who is also the proponent of LSTM), allows artificial intelligence to carry out the future state of the external environment in "dream". Forecasting, greatly improving the efficiency of completing tasks. Once this paper was presented, it attracted a lot of heated discussion. Humans develop a mental model of the world based on limited sensory perception, and all our decisions and behaviors are based on this internal model. Jay Wright Forrester, the father of system dynamics, defines this mental model as: "The world around us is just a model in our brains. No one's brain can imagine the whole world, all governments or countries. He only chooses concepts and their relationships, and then uses them to represent real systems." In order to deal with the vast amount of information in our daily life, the brain learns to represent the time and space abstraction of information. We can observe a scene and remember its abstract description [5, 6]. There is evidence that our perception at any time is determined by future predictions made by the brain based on internal models [7, 8]. Figure 2: What we see is based on the brain's prediction of the future (Kitaoka, 2002; Watanabe et al., 2018). One way to understand a predictive model in the brain is that it may not predict the future, but rather predict future sensory data based on the given current motion [12, 13]. In the face of danger, we are able to instinctively act on this predictive model and perform fast reflex behaviors [14] without the need to consciously plan a series of actions. Take baseball as an example [15]. Baseball batters only have a few milliseconds to decide how to swing the bat, and the visual signal of the eye takes less time to reach the brain. The batter can quickly act on the brain's predictions of the future without having to consciously launch multiple future scenarios before planning [16]. In many reinforcement learning (RL) [17, 18, 19] questions, artificial intelligence also benefits from good representation of past and present states, as well as excellent future prediction models [20, 21], preferably on general-purpose computers. A powerful predictive model of implementation, such as the Recurrent Neural Network (RNN) [22, 23, 24]. Large RNNs are highly expressive models that can learn data-rich temporal and spatial characterization. However, many of the model-free RL methods in the literature typically use only small neural networks with a small number of parameters. The RL algorithm is usually limited by the credit assignment problem, which makes it difficult for traditional RL algorithms to learn the millions of weights of large models. Therefore, small networks are often used in practice because they are more iterative during training. Fast, can form an excellent strategy. Ideally, we want to be able to efficiently train agents based on large RNN networks. Backpropagation algorithms [25, 26, 27] can be used to efficiently train large neural networks. In this study, we attempted to train a large neural network capable of solving RL tasks by dividing the agent into a large world model and a small controller model. We first train a large neural network in an unsupervised way to learn the model of the agent world and then train a small controller model to perform tasks using the world model. The small controller allows the algorithm to focus on the credit allocation problem in small search spaces without sacrificing the capacity and expressive power of large world models. By training the agent through the world model, we find that the agent learns a highly compact strategy to perform tasks. Although there are a large number of studies related to model-based reinforcement learning, this article does not summarize the current state of the field. This paper aims to extract several key concepts from a series of papers [22, 23, 24, 30, 31] that combined the RNN world model and controllers from 1990 to 2015. We also discussed other related research, and they also used a similar idea of ​​"learning the world model and then using the model to train agents." This paper proposes a simplified framework. We use the framework to experiment and prove some key concepts in these papers. It also shows that these ideas can be applied to different RL environments efficiently. The terms and symbols we use are similar to [31] when describing methodology and experimentation. 2. Agent model We propose a simple model inspired by the human cognitive system. In this model, our agent has a visual perception module that compresses what you see into a small, representative code. It also has a memory module that predicts future code based on historical information. Finally, the agent has a decision module that only bases actions based on characterizations created by its visual and memory components. Figure 4: Our agent contains three modules that are closely connected: visual (V), memory (M), and controller (C). 2.1. VAE (V) model The environment provides a high-dimensional input observation for our agent at each time step. This input is usually a 2D image frame in the video sequence. The task of the VAE model is to learn the abstract compressed representation of each observed input frame. Figure 5: Flow chart of the VAE. In our experiments, we used a variational self-encoder (VAE) (Kingma & Welling, 2013; Jimenez Rezende et al., 2014) as the V model. 2.2. MDN-RNN (M) model Although the idea of ​​compressing the agent on each time frame is the task of the V model, we also want to compress all changes that occur over time. To achieve this, we let the M model predict the future, which can serve as a predictive model of the future z-vector that V expects to produce. Since many complex environments in nature are random, we train the RNN to output a probability density function p(z) instead of a deterministic prediction z. 2.3. Controller (C) Model During the development of the environment, the controller (C) is responsible for determining the progress of the action to maximize the accumulated rewards expected by the agent. In our experiments, we made the C model as simple and small as possible, and trained V and M separately, so that most of the complexity of the agent is in the world model (V and M). 2.4. Merging V, M, and C The following flow chart shows how V, M, and C interact with the environment: Figure 8: Flow chart of the agent model. The original observation is performed on V at each time step t to zt. The input to C is the concatenation of the hidden vector zt with the M hidden state at each time step. C then outputs the motion vector to control the motor, which affects the entire environment. M then takes zt as input and generates state ht+1 for time t+1. 3.Car Racing experiment In this chapter, we describe how to train the agent model described above and use it to solve the Car Racing task. As far as we know, our agent is the first solution to solve this task and get the expected score. In summary, the Car Racing experiment can be divided into the following processes: 1. Collect 10,000 rollouts from a random strategy. 2. Train VAE(V) to encode the video frame into a 32-dimensional hidden vector z. 3. Train the MDN-RNN(M) to model the probability distribution P(z_{t+1} | a_t, z_t, h_t). 4. Define controller (C) as a_t = W_c [z_t, h_t] + b_c. 5. Use CMA-ES to solve W_c and b_c to maximize the expected cumulative reward. Table 1: CarRacing-v0 scores for various methods. Because our world model can model the future, we can assume or anticipate the racing scene on our own. Given the current state, we can ask the model to generate a probability distribution of z_{t+1} and then sample it from z_{t+1} and use it as a real-world observation. We can put the trained C back into the expected environment generated by M. The diagram below shows the envisioned environment generated by the model, and the online version of the paper shows the operation of the world model in the envisioned environment. Figure 13: Our agent learns to drive in its own envisioned environment or "dream." Here, we deploy the trained strategy to the forged environment generated from MDN-RNN, bintonggu and show it through the VAE decoder. In the demonstration, we can override the actions of the agent and adjust τ to control the uncertainty of the environment generated by M. 4. VizDoom experiment If our world model is accurate enough to handle the problem at hand, then we should be able to replace the world model with the actual environment. After all, our agents don't look at reality directly, they just look at the things that the world model presents to it. In this experiment, we train agents in the illusion generated by the world model that mimics the VizDoom environment. After a period of training, our controller learned to find a way in a dream, fleeing the fireballs shot of the M model to generate monsters. Figure 15: Our agent finds a strategy to escape the fireball in the illusion. We tested the agents trained in the virtual illusion in the original VizDoom scene. Figure 16: Deploying the strategies learned by the agent in the illusion RNN environment into a real VizDoom environment. Since our world model is just an approximate probability model of the environment, it occasionally generates trajectories that do not follow the rules of the real environment. As mentioned earlier, the world model does not even accurately reproduce the number of monsters on the other end of the room in the real environment. Just like a child who knows that an airborne object will always land, he will also imagine a superhero flying over the sky. To this end, our world model will be utilized by the controller, even if it is not present in a real environment. Figure 18: After the agent was hit by a fireball in multiple runs, it found a countermeasure against the automatic extinguishing of the fire ball. 5. Iterative training process In our experiments, the task was relatively simple, so a data set collected using a stochastic strategy could train a better world model. But what if the complexity of the environment increases? In a difficult environment, after the agent learns how to strategically cross its world, it can only acquire a part of the world's knowledge. More complex tasks require iterative training. We need agents to explore our own world and continuously collect new observations so that our world model can be continuously improved and refined. The iterative training process (Schmidhuber, 2015a) is as follows: 1. Initialize M and C using random model parameters. 2. Test run N times in a real environment. The agent may learn during the run. Save all actions a_t and observations x_t in the run on the storage device. 3. Training M models P(x_t+1, r_t+1, a_t+1, d_t+1|x_t, a_t, h_t). 4. If the task is not completed, return to step 2. Paper: World Models Abstract: We explore the generation of neural networks under the popular reinforcement learning environment. Our "world model" can be quickly trained in an unsupervised manner to learn the limited space-time representation of the environment. By using features extracted from the world model as input to the agent, we can train a very tight and simple strategy to solve the target task. We can even train our agents entirely through the illusory dreams generated by the world model itself, and move the strategies learned from them into the real environment. 5G Industrial Router,Industrial Lte Router Poe,Industrial Security Router,Industrial 5G Cellular Router Shenzhen MovingComm Technology Co., Ltd. , https://www.movingcommiot.com